Optics: Pulling Google Spreadsheet and Salesforce.com data into Elasticsearch

Above: The basic architecture of what I build as part of this blogpost.
I’m not trying to knock Salesforce.com (SFDC) reporting. My last three companies have used SFDC to track our software sales business and we love the hell out of it. The problem is we are staring to expect way more out of our data, and Elatic’s Solutions Architects (who I have the pleasure of being part of) are no exception. I was given a challenge: Help your team mates get insight and optics into our performance data. Working at Elastic I knew just the tool, Kibana!. Now the only challenge would be getting data out of the various Google spreadsheets and SFDC “objects” and into an Elasticsearch instance.
Side note: “why didn’t I just use logstash-input-salesforce?”. I didn’t really have a handy place to put a logstash instance and my SFDC admin didn’t give me the ability to register a new API app. The approach below allows me to run using raw REST through the a python SFDC client, which I found quicker for my needs (especially since my full version does all kinds of enrichment, pivoting, and extra full traversals of the data in-memory, whoch wouldn’t be possible in logstash)
Step 1: Provision Elasticsearch and Kibana (ELK) in the cloud.
This is actually the easiest step. Using Elastic Cloud (the recently rebranded Found.no) I can provision the latest Elastic stack and be up and running with and SSL secured private instance of Elasticsearch (2.3.0 at the time of writing) and Kibana (4.5.0) with Shield, Marvel, Graph, etc for abotu $45 a month.

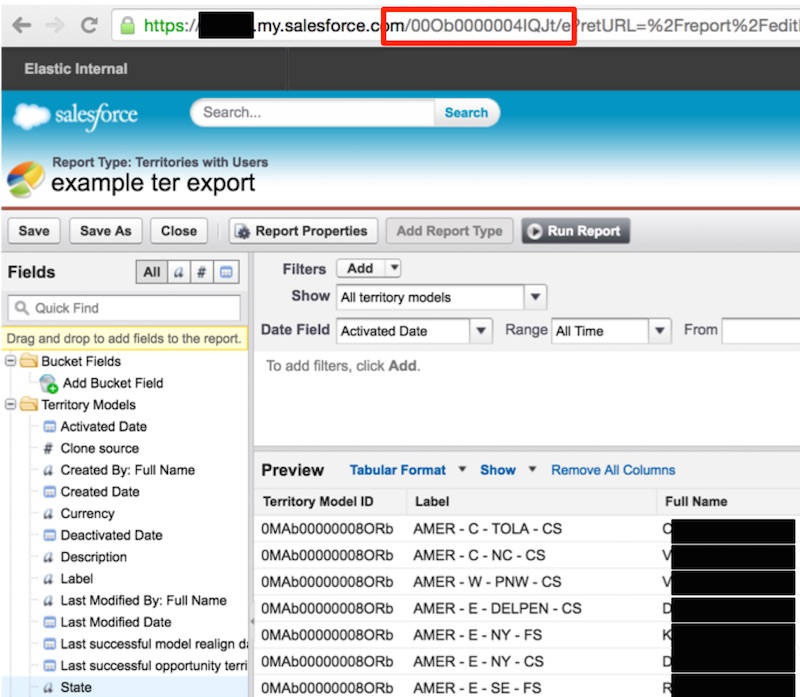
Above: The id of the report is in the address bar.
Step 2: Get your Salesforce Tokens
We are going to get data from SFDC using a python library called simple-salesforce
This was actually quite difficult to figure out. The SFDC API documentation (along with just about everything else on the planet) assumes you are making a 3rd party app acting on behalf of a user rather than just an internal script to to get your own company’s data. I like OAuth just fine, but when speed is of the essence I like cheating and doing direct pulls with the simpler authentication handshakes given I’m not trying to repackage a 3rd party app as a SFDC ecosystem product.
The answer I was looking for was in the comments of this knowledgebase artical. In SFDC an individual can generate a security token that can be used to programatically pull data as that user by going to: My Settings > Personal > Reset My Security Token

Above: The page in SFDC to get your security token.
To programatically pull data you’ll need your account’s email address, password, your comapany’s subdomain (something like MYCOMPANY.my.salesforce.com) and your security token
Step 3: Get your Google Spreadsheet API keys
We are going to get data from Google spreadsheets using the libraries gspread and oauth2
The Oauth2 link above has good instructions for getting your API key in JSON form. This will in effect create a new account email that can you can “share” a spreadsheet to make it readable by a python script.
Step 4: Accessing a SFDC report from python
First of all, every SFDC report has an ID in the address bar that can be used in the SFDC apis. The simple-salesforce python library has all kinds of helper methods to get to standard SFDC objects, but we’ll just use it to get an authenticated session id and pull whole reports at a time throught the request API and the handy python requests library.
The folllowing is the report I’ll grab. Note the ID in the address bar.

Above: The id of the report is in the address bar.
Below is my code for accessing the report in python:
import csv
from simple_salesforce import Salesforce
import requests
import base64
import cStringIO
import json
sf_instance_name = 'ORG.my.salesforce.com'
sf_user = 'SF_USER'
sf_pw = 'SF_PW'
sf_token = 'SF_TOKEN'
sf = Salesforce(username=sf_user, password=sf_pw, security_token=sf_token)
sf_sid = sf.session_id
## take a dictionary and print it's pretty json representation
def prettyPrint(doc):
print json.dumps(doc, indent=4, sort_keys=True)
## Function to go get a SFDC report by id and return a csvreader
## has a built in caching against disk so as not to spam SFDC service during development
## returns csvReader
def sFDCReportToCSVReader( sfdc_report_id, sfdc_obj, sfdc_instance_name, sfdc_sid, useCache, cacheData ):
if not useCache:
r = requests.get("https://"+sfdc_instance_name+"/"+sfdc_report_id+"?view=d&snip&export=1&enc=UTF-8&xf=json&includeDetails=true", headers = sfdc_obj.headers, cookies = {'sid' : sfdc_sid})
r.encoding = 'utf-8'
requestCSVText = r.text.encode('utf-8')
if cacheData:
outFile = open(sfdc_report_id+".csv", "w")
outFile.write(requestCSVText)
outFile.close()
buf = cStringIO.StringIO(requestCSVText)
return csv.DictReader(buf)
else:
my_file = open(sfdc_report_id+".csv", "r")
return csv.DictReader(my_file)
## Load report from SFDC to a python dictionary
territoryMappings = {}
report_id = "00Ob0000004IQJt"
csvreader = sFDCReportToCSVReader( report_id, sf, sf_instance_name, sf_sid, False, False )
counter = 0
for row in csvreader:
fullName = row["Full Name"]
## check for a valid name, CSV export from SFDC has metadata at the end
if(fullName != None):
counter = counter + 1
_id = row["Label"]
doc = {
"territoryId": row["Territory Model ID"],
"label": _id,
"fullName": fullName
}
if( _id in territoryMappings):
territoryMappings[_id].append(doc)
else:
territoryMappings[_id] = [ doc ]
prettyPrint(territoryMappings)
And the result:
$ python test.py
{
"AMER - C - LACA": [
{
"fullName": "REDACTED",
"label": "AMER - C - LACA",
"territoryId": "0MAb00000008ORb"
},
{
"fullName": "REDACTED",
"label": "AMER - C - LACA",
"territoryId": "0MAb00000008ORb"
},
{
"fullName": "REDACTED",
"label": "AMER - C - LACA",
"territoryId": "0MAb00000008ORb"
},
...
As we can see SFDC’s APIs make it easy to get any report as a CSV. From that point on it’s just data and we are golden. Companies with higher transacational business may need to page and scroll through huge report tables, but as a company that sells larger ‘enterprise’-y things, I can get the full history of the compay in a single REST call.
Aside: it’s worth noting that all these huge exports are backed by a large Oracle deployment at SFDC. Good on you Oracle.
Step 5: Getting Google Spreadsheet data
Create a new spreadsheet in google dive (a.k.a google sheets, a.k.a. google spreadsheets, a.k.a. google docs, somebody has a naming problem).

Above: Sample data.
Google Forms can save their data to Google Spreadsheets, becoming a poor primary data store for data to later be indexed in Elasticsearch. If you go to the sharing options and share the sheet to the email adrress from your API key in step 3.
The following code then helps grab a google spreadsheet and convert it to a python dictionary:
import json
import gspread
from oauth2client.client import SignedJwtAssertionCredentials
keyFilePath = "ESGSpreadsheetPull-HASHHASHHASH.json"
spreadsheetKey = "1n2ivenC_fb34xX6asWe9IDDXyp50oiMbpYS7rOhpIls"
worksheetName = "Sheet1"
json_key = json.load(open(keyFilePath))
scope = ['https://spreadsheets.google.com/feeds']
credentials = SignedJwtAssertionCredentials(json_key['client_email'], json_key['private_key'], scope)
gc = gspread.authorize(credentials)
sh = gc.open_by_key(spreadsheetKey)
ws = sh.worksheet(worksheetName)
list_of_lists = ws.get_all_values()
def prettyPrint(doc):
print json.dumps(doc, indent=4, sort_keys=True)
rows = []
counter = 0
for row in list_of_lists:
if(counter == 0):
counter = counter + 1
continue
doc = {
"A": str(row[0]),
"B": str(row[1]),
"C": str(row[2])
}
rows.append(doc)
counter = counter + 1
for row in rows:
prettyPrint(row)
and the result:
$ python test2.py
{
"A": "1",
"B": "2",
"C": "3"
}
{
"A": "4",
"B": "5",
"C": "6"
}
Step 6: Exporting to Elasticsearch
I’ll leave this step to the reader. Looping through objects in a dictionary and exporting to Elasticsearch using the Elasticsearch client for python isn’t too difficult.
Step 7: Running the code on a schedule inside Heroku
Go through the first few steps of the Heroku getting started guide for python.
Create a new project folder and create a requirements.txt file with your python code’s dependencies:
APScheduler==3.1.0 elasticsearch==1.4.0 moment==0.2.2 simple-salesforce==0.68.1 requests==2.7.0 requests-oauthlib==0.6.0 gspread==0.2.5 oauth2==1.9.0.post1 oauth2client==1.4.12 oauthlib==1.0.3
Create a Procfile declaring a background job that calls a main.py script
background: python main.py
Put wrapper code around your SFDC and Google spreadsheet code (main.py):
#!/usr/bin/python
# -*- coding: utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
### IMPORTS GO HERE
def runSFDCJob():
print "Run SFDC Jobs"
## CODE GOES HERE
dev runGSJob():
print "Run Google Spreadsheet Job"
## Code GOES HERE
@sched.scheduled_job('interval', minutes=10)
def timed_sfdc_job():
print('Starting Timed SFDC Job')
runSFDCJob()
@sched.scheduled_job('interval', minutes=10)
def timed_gs_job():
print('Starting Timed Google Spreadsheet Job')
runGSJob()
print "Running jobs once each before starting the scheduler"
runSFDCJob()
runGSJob()
## start the scheduler, which is a blocking action,
## so no point having code after the start line
print "Starting Scheduler"
sched.start()
create a new heroku project
heroku create
Give the heroku project a dyno
heroku ps:scale background=1
And push the code to heroku
git push heroku master
Now you should have your SFDC and Google spreadsheet data pushing to your Elastic Cloud instance! The major benefit of course being far superior discovery and charting with Kibana

Above: reporting on an audit trail on Opportunities, showing in what stage my team ‘tags’ themselves on deals.

Above: a graph analysis of Solutions Architects who collaborate on deals together; because we are all about team work